해시 알고리즘은 데이터를 왜곡하여 읽을 수 없게하는 수학 함수입니다.
이는 단방향 알고리즘으로 다른 사람이 텍스트를 해독하거나 디코드할 수 없게 하는 것이 해시의 핵심 개념입니다. 해시는 유휴 데이터를 보호하므로, 다른 사용자가 서버에 접근해 코드를 읽어낸다 해도 저장된 내용을 알아낼 수 없습니다.
또한 작성자가 데이터를 만든 후 데이터가 변경되지 않았다는 것을 증명하기위해 사용할 수 있습니다. 때로는 해시를 사용해 큰 데이터의 무결성을 확인할 수 있습니다.
Table of Contents
해시 알고리즘 이란?
수십 개의 해시 알고리즘이 존재하며 모두 다르게 동작하지만, 사용자는 데이터를 입력할 뿐이고 알고리즘이 이를 여러 형태로 바꿔주는 것이 전부입니다.
모든 해시 알고리즘은 다음과 같은 특징을 가집니다:
- Mathematical: 알고리즘이 수행하는 작업에는 엄격한 규칙이 적용되며 이러한 규칙은 깨지거나 조정될 수 없습니다.
- Uniform: 한 가지 유형의 해시 알고리즘을 선택하면 시스템을 통해 입력되는 모든 문자 데이터는 알고리즘에서 미리 결정한 길이로 나타납니다.
- Consistent: 알고리즘은 한 가지 작업(데이터 축소)만 수행하고 다른 작업은 수행하지 않습니다.
- One way: 알고리즘에 의해 변환되면 데이터를 원래 상태로 되돌리는 것은 불가능합니다.
해시와 암호화는 서로 다른 기능이라는 것을 이해해야 합니다.
이들을 서로 조합하여 사용할 수는 있지만 각각의 용어를 같은 의미로 사용하지 마십시오.
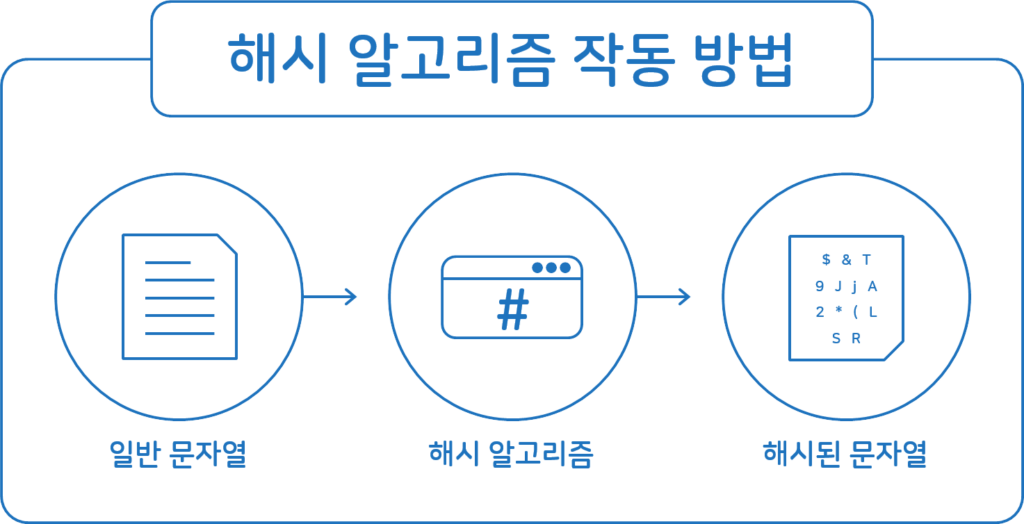
해시 알고리즘 작동 방법
계산기, 표, 기본적인 수학에 대한 이해만 있으면 알고리즘을 만들 수 있습니다. 하지만 요즘 사람들은 컴퓨터를 사용합니다.
대부분의 해시 알고리즘은 다음 프로세스를 따릅니다:
- Create the message: 사용자는 해시할 항목을 선택합니다.
- Choose the type: 수십 개의 해시 알고리즘이 존재하며 사용자는 선택한 메시지에 가장 적합한 알고리즘을 결정합니다.
- Enter the message: 사용자는 알고리즘을 실행할 컴퓨터에 메시지를 입력합니다.
- Start the hash: 시스템은 임의 길이의 메시지를 미리 결정된 비트 길이로 변환합니다. 알고리즘은 메시지를 일련의 블록으로 나누고 각 블록을 순차적으로 축소합니다.
- Store or share: 사용자는 해시(“message digest”라고도 함)를 의도한 수신자에게 보내거나 해시된 데이터를 지정된 형식으로 저장합니다.
프로세스는 복잡하지만 실제 작동은 매우 빠릅니다. 대부분 몇 초 안에 해시가 완료됩니다.
해시 알고리즘의 용도
1958년에 개발된 최초의 해시 알고리즘은 데이터를 분류하고 구성하는 데 사용했습니다. 그 후로 개발자들은 이 기술의 수십 가지 용도를 발견했습니다.
개발자는 다음을 위해 해시 알고리즘을 사용할 수 있습니다:
- Password storage: 서버 관리자는 리소스 액세스에 필요한 모든 사용자 이름/암호 조합을 기록해 두어야 합니다. 그러나 해커가 진입하면 보호되지 않은 데이터를 훔치기 쉽습니다. 해싱은 데이터가 스크램블된 상태로 저장되도록 하므로 사용자 정보를 훔치기가 더 어렵습니다.
- Digital signatures: 메모형태의 아주 작은 데이터를 통해 송신된 메일이 수신될 때 까지 수정되지 않았음을 증명합니다.
- Document management: 해시 알고리즘을 사용하여 데이터를 인증할 수 있습니다. 최초 문서 작성자는 문서 작성을 마쳤을 때 해시를 사용하여 문서를 보호합니다. 해시는 승인의 도장처럼 작동합니다. 수신자는 받은 문서에서 해시를 생성하여 원본과 비교할 수 있습니다. 둘이 같으면 데이터가 진짜인 것으로 간주됩니다. 일치하지 않으면 문서가 변경된 것입니다.
- File management: 일부 회사는 해시를 사용하여 데이터를 인덱싱하고 파일을 식별하며 중복 항목을 삭제하기도 합니다. 시스템에 수천 개의 파일이 있는 경우 해시를 사용하면 상당한 시간을 절약할 수 있습니다.
간단한 예제
이러한 특수 알고리즘이 실제로 작동되는 모습을 보지 않는다면 어떻게 작업이 진행되는지 알기 어려울 것 입니다.
보안 질문에 대한 답변을 해시하고 싶다고 가정해 보겠습니다.
먼저 “당신의 첫 번째 집은 어디였습니까?”라고 묻고 이에 대한 답으로 “퀸즈에 있는 아파트 건물 꼭대기”라고 한 경우 해시는 다음과 같이 표시됩니다.
- MD5: 72b003ba1a806c3f94026568ad5c5933
- SHA-256: f6bf870a2a5bb6d26ddbeda8e903f3867f729785a36f89bfae896776777d50af
이제 다른 사람에게 같은 질문을 했다고 생각해 보겠습니다. 다른 사람은 “시카고”라고 답한 경우 해시의 모양은 다음과 같습니다:
- MD5: 9cfa1e69f507d007a516eb3e9f5074e2
- SHA-256: 0f5d983d203189bbffc5f686d01f6680bc6a83718a515fe42639347efc92478e
위의 예제에서 답변된 메시지의 문자 수는 동일하지 않습니다. 그러나 알고리즘은 매번 일관된 길이의 결과를 생성합니다.
그리고 결과 문자열을 완전히 읽을 수 없다는 것도 알 수 있습니다. 원래 답변이 뭐였는지 어떻게 이렇게 만든건지 거의 알아낼 수 없습니다.
널리 사용되는 알고리즘
다양한 유형의 알고리즘이 텍스트를 변환할 수 있으며 모두 조금씩 다르게 동작합니다.
일반적인 해시 알고리즘은 다음과 같습니다:
- MD-5: 이는 널리 인정된 최초의 알고리즘 중 하나입니다. 1991년에 설계되었으며, 당시에는 매우 안전하다고 여겼습니다. 그 후로 해커들은 알고리즘을 해독하는 방법을 발견했으며 몇 초 만에 해독됩니다. 현재 전문가들은 MD-5가 쉽게 해독되기 때문에 사용하기에 안전하지 않다고 말합니다.
- RIPEMD-160: RACE Integrity Primitives Evaluation Message Digest (or RIPEMD-160)은 1990년대 중반 벨기에에서 개발되었습니다. 해커들이 암호를 해독하는 방법을 아직 정확히 파악하지 못했기 때문에, 이는 꽤 안전하다고 여겨집니다.
- SHA: SHA 제품군의 알고리즘은 약간 더 안전한 것으로 간주됩니다. 첫 번째 버전은 미국 정부에서 개발했지만 다른 프로그래머들이 원래 프레임워크를 기반으로 더 엄격하고 깨지기 어렵게 만들었습니다. 일반적으로 “SHA” 문자 뒤의 숫자가 클수록 최신 릴리스이고 프로그램이 더 복잡합니다. 예를 들어 SHA-3는 코드에 임의성 소스를 포함하므로 이전 코드보다 크랙하기가 훨씬 더 어렵습니다. 그런 이유로 2015년에 표준 해시 알고리즘이 되었습니다.
- Whirlpool: 2000년에 설계자들은 Advanced Encryption Standard(AES)를 기반으로 이 알고리즘을 만들었습니다. 이또한 매우 안전한 것으로 간주됩니다.
미국 정부는 더 이상 해사 알고리즘 작성에 관여하지 않습니다. 하지만 데이터를 보호하는 역할은 맡고있습니다.
National Institute of Standards and Technology가 부분적으로 실행하는 Cryptographic Module Validation Program은 암호화 모듈의 유효성을 검사합니다.
개발자는 이 리소스를 사용하여 안전하고 효과적인 기술을 사용하고 있는지 확인할 수 있습니다.